Human pose estimation via Convolutional Part Heatmap Regression,通过卷积的人体部分热点图回归的人体姿态估计
诺丁汉大学,计算机视觉实验室。本文发表于2016年。
评价:此架构主要关注预测被遮挡的部分,架构相对比较简单,主要通过2层结构的方式,用第一层学到的结果作为第二层的输入,得到了比较好的效果。不过,对于三维估计、实时处理以及多人的情况,本文并未论述。本文可以作为其他类型姿态估计的基础。
Abstraction
主要贡献:建立了一个CNN串联的结构,能够学习(人体)各部分之间的关系,以及空间背景,并且即使在人体部分被严重遮挡的情况下,也能预测出人体姿势。串联的第一部分,生成人体部分检测热点图;第二部分,对这些热点图进行regression;
有好几个好处:
第一,能够引导网络,应当专注在图片的哪个地方,并有效的对人体部分的约束和图片环境进行编码。
第二(更重要的),能够有效处理被遮挡的部分,因为被遮挡部分的人体部分检测热点图的得分比较低,随后能够引导regression部分更依赖于上下文信息来预测这些被遮挡的部分。
此外,这种串联的结构适用于各种CNN结构,包括最近的残差学习residual learning。最后,这个网络在MPII和LSP数据集上取得最好的成绩。
代码地址:https://github.com/1adrianb/human-pose-estimation 另外,有一个新的用于检测人体姿态和人脸校准(???)的代码,能够在运算能力较小的设备上运行:
Introduction
人体姿态估计是计算机视觉领域的一个很困难的问题。关键问题在于,如何能够提取低级-中级特征和相关的环境信息,并且model复杂的人体部分之间的关系,以能够有效预测人体姿态。CNN能够有效解决这个问题,但是对于被遮挡部位的估计仍然很难。本文所提出的串联结构就是为了解决这个问题。
以前有通过计算机视觉的传统算法的尝试,主要基于图形结构,通过一组严格的模板,以及一组pairwise potentials,通过树状形式实现。最近的尝试包括一些扩展,包括mixture,hierarchical,多通道,strong appearance models,非树结构,以及串联/连续预测模型(比如pose machines)。
对于CNN来说,人体姿态估计是一个regression问题。对于被遮盖部分,学习其具体部位仍然很难,需要依赖于周围环境(包括其他部位的位置)。本文的方式,通过先detection再regression的方式,规避了这个问题。
主要贡献
第一部分是一个CNN,为每一个部位进行预测,形成一个预测热点图。部位预测是jointly(如何jointly???softmax)训练的,loss function是pixelwise(per pixel) sigmoid cross entropy。第二部分将所有的part heatmap和原图一起作为输入进行confidence map regression,以得出最终的body parts热点图。
关键点在于,第一部分的预测为第二部分的regression提供了指引;另外,此结构克服了被遮盖部分的预测问题:因为被遮盖部分的heatmap显示了置信度比较低,所以regression更依赖于其与其他部分的关系。最终的结果,不仅被遮挡部位预测的很好,可见部分的预测也更加精准,置信度更高。
此结构很简单,可以适用于不同CNN结构,本文提供了2个例子:VGG转换而来的FCN,以及残差学习ResNet。
相关的工作
过去工作的总结:最近提出的用于人体姿态估计的方法主要分为两类:基于detection,以及基于classification。基于detection的方法依赖于高效的基于CNN的部位估计,然后和图模型结合,或者通过regression重新定义。基于regression的方法尝试构建从图片+CNN feature到部位位置的映射。。。(需要继续读论文)
本文方法和基于regression的方法之间的关系:
本文方法和基于detection的方法之间的关系:
残差学习:
具体方法
第一部分通过对像素的softmax loss(到底是softmax还是sigmoid???是两者的结合?)来预测部位,其输出是一组N个部位预测的heatmaps。
第二部分将堆叠在图片上的部位预测heatmaps(就是CNN features?)regresssion到表示人体部位的confidence maps。
实现了两个例子。第一个例子用了两个VGG-FCN网络,第二个例子用了两个ResNet。
对于detection部分,将所有的part的label转换成N个0-1 map:靠近某个ground-truth位置的半圆为1,其余位置为0。解决了某个像素点数据重叠的问题。半径的选择:能够将人眼看到的部位全部覆盖。对于200像素的人,半径选择10像素。
loss function(sigmoid交叉熵):
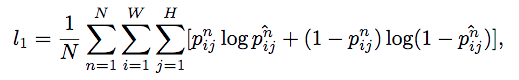
其中,pnij表示第i,j个像素在第n个部位的ground truth,另外一个代表预测值。当两者相近时,loss接近0;当两者远离时,loss较大。
对于regression部分,regress正确位置附近的一组位置,而非一个单一位置。ground truth和预测值被高斯模糊化,标准差为5px;防止预测位置只要不是在正确位置上,loss就不降低的问题。
loss function(L2 Loss):
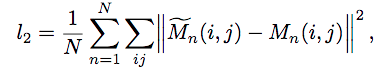
VGG-FCN:
detection部分:
将全连接层转换为kernel size为1的卷积层。
VGG19层,加上带trick的上采样,将精度从32px提高到8px;
regression部分:
7层卷积层和1层反卷积层。前几个kernel size比较大(9-15),以覆盖大范围的特征。
训练
所有的人都被切出来,然后scale成同样的尺寸。尺寸为380*380;做了数据增强(翻转,放大缩小,旋转)。
在regression部分,所有layers用高斯分布初始化(标准差为0.01)
ResNet:
ResNet-152网络;稍微修改了一下。其他和VGG-FCN差不多。
效果
效果检测方法:PCKh matrix。
比2步Regression的效果好。
先detection再regression是有用的。
ResNet的效果比VGG-FCN好。
和其他几种的比较:只有detection;只有regression;两步regression;
最佳效果:detection+regression,同时选择ResNet;